
Support Vector Machines for Image Classification
Theoretical Background and Implementation through the Example of Leaves
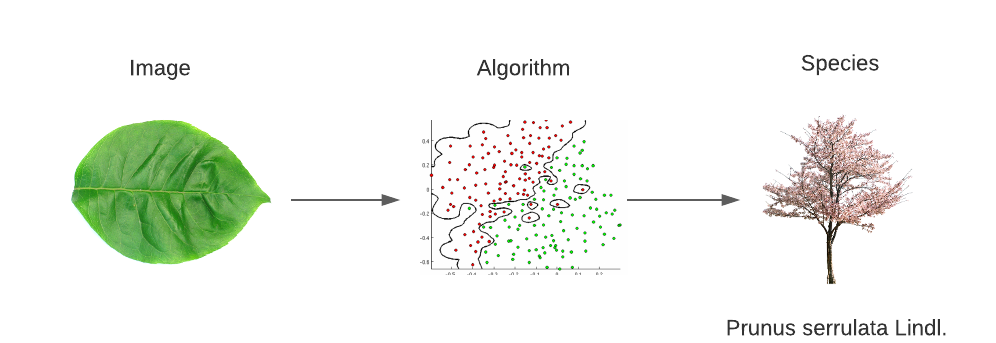
Objectives
My personal objective with this project was to learn about the mathematical background and application of machine learning algorithms in the scope of my Matura thesis. After an initial research phase outside this project, I decided to focus on support vector machines (SVM) as they were, at that time, challenging but feasible for me.
As this project is a thesis it consists of a theoretical and practical part.
Theoretical Part
- Linear Classification Algorithms
- Support Vector Machines
- Soft Margin Support Vector Machines
- Kernel Functions
Practical Part
- Implementation of an SVM from scratch
- Image Processing
- Train the SVM with leaves
Implementation
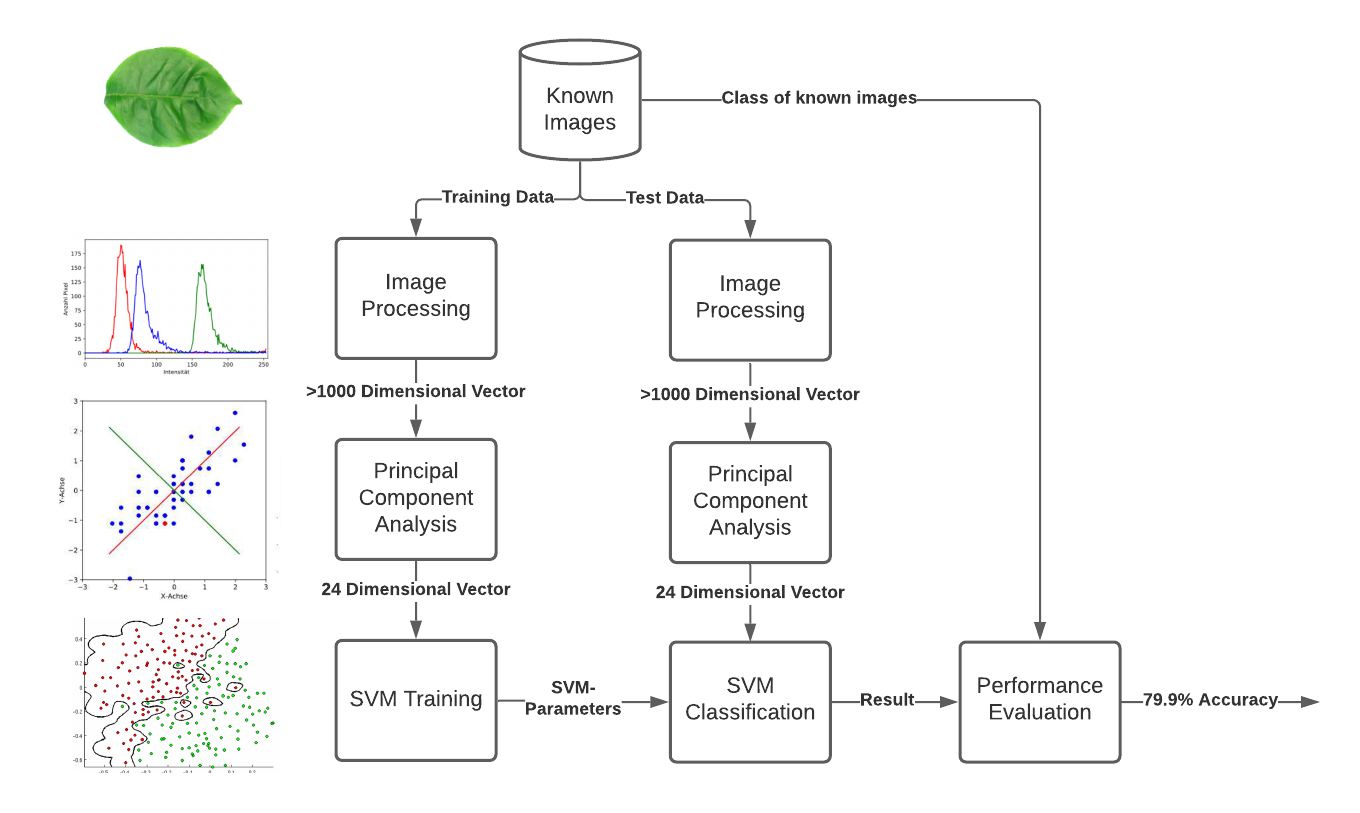
As shown in the visual project summary above, everything starts with a database containing images of known leaves. Those images are split into a training set (80%) and a testing set (20%). The latter does is not considered during the training and tuning of the algorithm and serves only as a new, unseen sample to evaluate the performance of the final design.
My software starts to reduce the images to a vector with >1000 dimensions using descriptor algorithms. Those algorithms quantitatively measure features of the images like e.g. the color distribution or shape parameters. Initially, I planned on using these vectors to train the SVM. However, this resulted in massive over-fitting as my training data set was too small compared to the number of features.
This problem can be solved in two ways: by reducing the features measured by the descriptors or by adding a principal component analysis (PCA). I decided on using the latter as this ensured that I chose only the most important features. Multiple tests showed that reducing the dimensions of the vector to 24 elements yielded the best results.
The next step is to use the generated vectors to train the support vector machine I implemented from scratch using python. There, I had to tune multiple parameters including the weighting factor for wrongly classified data points and the used kernel function.
Finally, the testing data is used to evaluate the performance of the design.
Results
Overall, my implementation correctly classified 89.7% of the leaves in my testing data. Most wrong classifications are due to the algorithm’s inability to distinguish between two of the 32 classes.
To further improve my design, I could have used additional algorithms (SVM or others) specially trained to compensate for the errors of the SVM. Additionally, Multiple algorithms with a majority vote could have been implemented to further improve the design and counteract weaknesses specific to SVMs.
Conclusion
This project taught me a lot of technical and non-technical skills.
First, I carried out a lot of research about commonly used machine learning algorithms, especially their functioning, strengths, and weaknesses before selecting the SVM. I learned about the problems associated with machine learning and strategies to fight them.
Second, this project, being my first thesis and hence first big report, introduced me to scientific writing, Zotero, and Latex. I learned to organize and carry out a bigger project.
I am happy that my thesis got nominated for the Niklaus Wirth Young Talent Computer Science Award where I could present my work at ETH Zürich.
I presented my work in the scope of an award at ETH Zürich.